Clustering & Visualizing Travelers' Stories with Doc2Vec and WebGL

Aug 05, 2019
In a time where it feels like differences between nations and their people are amplified, I hope this project serves as reminder that many of us are connected through the way we experience our planet and each other.
Motivating Story
Although I occasionally find the time to write down musings about life and the universe, they rarely are the kind of stuff that’d captivate your imagination. In contrast, my wife Olivia is a talented story teller and writer. One of her goals during our sabbatical was to work on a short story. Naturally she was the trip’s official travel writer and sent out a few diary-emails to friends and family, who without a fail wrote back every time with great praise.
So when I found out that our travel insurance provider (WorldNomads) was sponsoring a travel writing contest, I convinced her to submit an excerpt. At first, I was certain that she’d win; however when we realized that there were over 10,000 submissions, it became obvious that the odds were not favorable.
Sure enough, the results came out, and she wasn’t event shortlisted. While disappointing, the whole thing got me thinking about how many other awesome stories must have been shared, and how few of them would be read. I found myself thinking about different questions:
- How did the judges go through so many stories and rate them?
- Wouldn’t it be great if they made those ratings available to see how she ranked?
- Unfortunately they didn’t - so how do I know how good or unique Olivia’s story was?
- Aside from the 3 winners and 10 shortlisted, how can I find other great stories?
- Given all of the data, would I be able to have a computer generate similar stories?
With this in mind, I set out to try to do something interesting with this dataset. I knew that it would be a challenge because aside from that Naive Bayes Spam Filter homework every CS student implements at some point, I don’t have any experience with natural language processing (NLP). Still, I figured it would be a good opportunity to learn how machine learning tools can be used with documents. This also coincided with our last week in Sri Lanka - exactly when the prospect to returning to real life started materializing, and I was feeling the urge to do something “fun” before getting back to a full-time job (little did I know it’d end up taking another 2 countries and 4 months before I’d finally start working again)

Exploring Stories
I did some research on what tools I could use to extract interesting relations between stories. I stumbled on Doc2Vec, an increasingly popular neural-network technique which converts documents in a collection into a high-dimensional vectors, therefore making it possible to compare documents using the distance between their vector representation.
But before digging into the technical details I think it’s worthwhile and fun to talk about how utterly cool the results are (it’s great writing on a blog - I wouldn’t be able to say this on a peer-reviewed paper!) You can scroll down to The How section to read about the scraper, the model building/tuning, and the designing/coding of the visualization website.
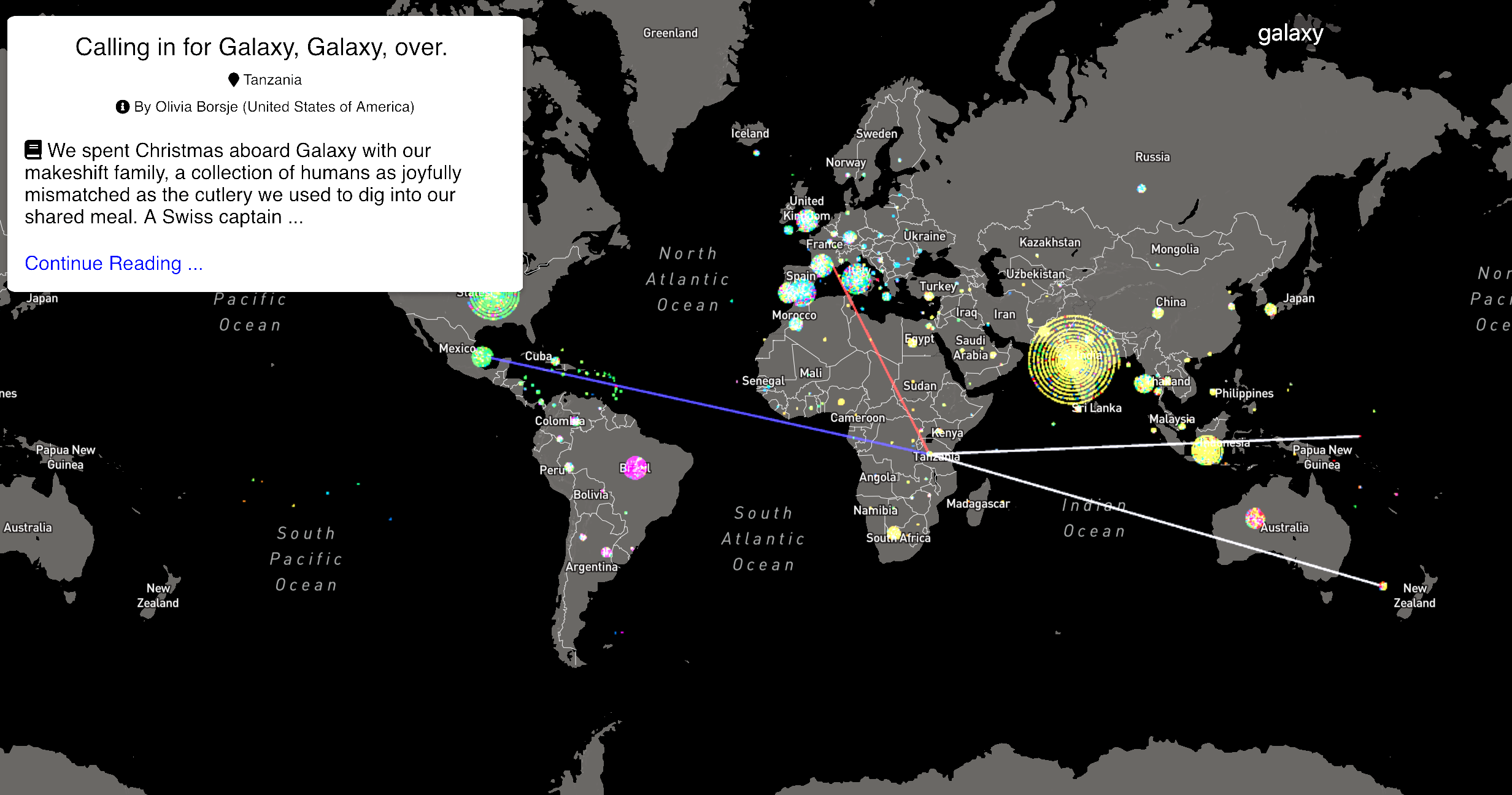
Calling in for Galaxy, Galaxy, over
That was the title of Olivia’s story. It was the radio transmission we’d hear when our friends wanted us to come over for dinner or needed to borrow the spare dinghy motor. The story is set on a sailboat off the coast of Zanzibar - an idyllic archipelago with deserted beaches and welcoming people. The intro went something like this:
We spent Christmas aboard Galaxy with our makeshift family, a collection of humans as joyfully mismatched as the cutlery we used to dig into our shared meal. A Swiss captain who travels the world before a degenerative eye disease takes it away. A Canadian couple mourning a baby. South African parents who found space for exploration within their empty nest. Molly the hound. And Zouhair and me. I wonder how others would describe us.
Out of the 10,000+ entries, the 2nd most similar story to Olivia’s was Justin’s The 12 Day Changeover whose intro quickly draws you in:
We travel by battered boat, seaweed-stained, but its tiller still works, its radio, its hand-cranked orange juicer. A fresh coat of pistachio. There is a crew of three: a captain, a navigator, a cook. One of them is a ghost; they know one of them is a ghost, hear the rattling chains every night, but the other two haven’t figured out which of them it is.
This alone feels like a mini-success: the model identified another story set on a sailboat, with a captain and some companions, and (if you squint) a similar writing style! The similarities are obvious, which is not too surprising as the two stories use a similar set of words given that they are both set on a sailboat.
But Let’s look at the story that is most similar to Olivia’s. According to the model, that would be Kirstin’s Take a Break. At first glance, it’s hard to identify the similarity with this tale of lost Australians in Mexico. Could it be that they are related because Kirstin talks about arriving at a beach and finding helpful people, and Olivia describes the curiosity of the children and warm welcome of the people when we land on Pemba’s beaches? Maybe, but I’d like to believe that the strong similarity comes from the stories’ concluding paragraphs. Here is Kirstin’s:
Every time we offer our assistance in the kitchen, Wiley pulls out his favorite catchphrase, “Take a break”. Still a child at heart, he’s in awe of our youthful moxie to leave everything behind to travel and his eyes glaze over as he dreams of a past in which he wishes he had done the same. We still can’t quite believe the generosity of Helen and Wiley to adopt us strays. Just two months later we learn that Wiley has suffered a stroke. It is one of those sobering, albeit cliché ‘life is too short, do it while you’re young’ moments.
And so we took a break.
And here is Olivia’s:
For all the wonder, there’s been equal hardship. The romantic vision paints this life, who knows no master but the weather, as the pinnacle of freedom. But I’ve felt stranded on this boat. Galaxy is urging me to sit still although the b*tch gets to rock constantly, and I resent her for it. […] Galaxy couldn’t care less about what I want. Maybe it’s because she’s been focused on giving me what I need instead. Time to stop and digest momentous life changes undertaken all at once. A chance to face my fears and find my edges. A view of the horizon, and what might lay right behind it.
And there it is - both have endings with mixed emotions. Despite the sudden death in one and the hardship in the other, both speak of the importance of taking time - to travel and to digest life.
…
Ok, you might think I’m blowing some hot air here, and that would be a fair criticism. It’s hard to tell though, as this illustrates one of the difficulties of neural-networks and other ML techniques: interpretability. The model says that based on the stories it was trained on, these two are similar, but it’s hard to know why without digging into its details. For example, the vocabulary it has encountered is important, and these stories are only similar within the context of the “corpus” it has seen so far. To get an intuition for that, checkout this (king - man) + woman = queen post which gives an analysis for Word2Vec, the basis behind Doc2Vec. Not being an NLP expert, I am not sure if there are similar ways to analyze the output of Doc2Vec to understand why two documents are similar. If you are one, hit me up :)

Geographical Clusters
So far I’ve focused on Olivia’s story, but I’ve spent hours reading various other ones for fun. I was soon finding myself doing a lot of this story comparison by hand: randomly selecting one from the corpus, and running code to display the most similar story to it. I wanted a more streamlined alternative that I imagined could be a great way to share all of these travelers’ stories with a wider audience.
At first I thought that maybe using the computed distances to generate a Dendrogram would expose interesting structures in the stories. However, it turned out that displaying a dendrogram with so many nodes is not very informative nor easy to use. Instead, I decided it’d be easier to start by laying out the stories geographically on a map.

Although the easiest to understand conceptually, it took the longest to get this view working because it was the first. I needed to find the right framework to use. I initially gravitated to using Plotly/Dash given my recent experience with it from the DivetheData project. But after a few false starts, I eventually settled on VivaGraphJS - hailed as the fastest graph visualization framework; and it lived up to its promise!
I chose to center the nodes at the locations were the stories were written, and to color them based on the continent of origin of the author. Since the metadata lacks the exact geographic location details, I got creative with the positioning and made collocated stories build up into a spiral. The resulting interface was colorful, fast, and smooth; and it quickly exposed some interesting insights:
-
Populated countries tend to have a large proportion of “local” travelers. The majority of the dots in the US are green (stories written by North-American travelers), likewise with India and Indonesia with yellow dots (stories by Asian travelers), Nigeria and South Africa with orange dots (stories by African travelers); and Brazil with purple dots (stories by South Americans). This is in contrast to popular tourist destinations which have more of a mix: The UK, France, Spain, Portugal, Italy, Morocco, Turkey, Thailand, Vietnam, Nepal, and Japan all have a mix of stories from writers all over the world.
-
Stories are rarely connected by their location. Except for India, if you quickly mouseover stories, you will see that the ones they’re connected to are often not set in the same country. I specifically avoided using any of the metadata (author country, submission category, etc.) in the model as I wanted only the story text to influence the relations.
-
The location of many stories are mis-labeled. If you take the time to read some of the entries, you will quickly realize that writers sometimes mistakenly put their country of origin as the location.
Similarity Constellations
Aside from a constant layout, VivaGraphJS implements Force Directed Graph Drawing, a super nifty way to layout graphs. It’s basically an N-body simulation where the links between nodes act as springs pulling related nodes together, therefore doubling as a clustering algorithm.
I initially attempted to do this with all of the connections, but there are too many and the result is a hot mess. However, when the links are restricted to the most similar connections only, the resulting graph is interesting. I like to think of it as a collection of constellations, each with a common thread, making it easier to explore stories by “topics”. Unfortunately, there is no elegant way to label the topics, as discussed in this Automatic Topic Clustering Using Doc2Vec which ends up using the most frequent occurring words in news articles titles.
Nonetheless, as one explores these constellations, it is interesting how clustered stories will often share similar settings (hiking, ocean, city/urban, airport, train, etc.). That is not surprising as even a rudimentary “bag of words” approach should be able to cluster them together. However, what’s ice-cold is when the similarities appear to be driven by the story’s structure or sentiment: being lost at the beginning and getting help from a local, trouble with immigration officers that eventually gets resolved, etc. Here are some specific ones I think are worthwhile to highlight.
Overcoming Fears Whether it’s fears of traveling alone, flying, sky-diving, or jumping off-boats; this is one of the biggest constellations and is self-explanatory. Here is a sample of the stories in the cluster:
- Fear is temporary, regret is forever This story by Sarah Corrigan (USA) about her study abroad in Australia is at the center of one of the biggest clusters. It contains almost all the elements found in the other ones: traveling alone, being held back by fear or social pressures, queasy feelings about/during flights, becoming more adventurous, and jumping!
- Riding Solo Michael Houston (UK) recounts overcoming his fear of traveling alone to Berlin.
- Introducing Kay Cabernet Kyndra Rothermel (USA) describes how she overcame difficulties of being an expat and eventually became an adrenaline junkie going paragliding and cage diving with sharks.
Nationality & Identity This cluster of stories describes the challenges that arise due a clash of Nationality, identity, and/or religion
- Hola Libertat! In this story Tsz Kwan Lam (Hong Kong) finds parallels between the Catalanians’ fight for preseving their distinct culture within Spain to his Hongkongese compatriotes fight for political freedom from China.
- My Dearly Beloved Br-EX-it London Yelena Novikova (Kazakhstan) describes how a “Brexit tantrum” makes its beloved host country “sound like a racially-charged bus fight” and blames it for almost being evicted from her rental.
- The Smile of Homeland Julya Fransisca relates the difficulties of growing ethnically Chinese in Indonesia.
- Lebanese Luster Richard Chemaly (South Africa) ponders how the Meronites’ fight for religious freedom has given rise to a unique beauty to Lebanon’s mountains.
Lost with Translation This is a bit of a complicated cluster to interpret, but I think it is basically a mix of buying tickets, not speaking the local language, getting lost, and getting help from locals:
- My Christmas Serendipity In an attempt to escape tourist-laden Munich, Zhanna Ganeva (Bulgaria) unexpectedly finds herself in Austria after buying a ticket to Salzburg.
- Russian glasses Giovanni D’Amico (Italy) struggles with Cyrillic alphabet but fortunately gets help from Masha with buying a train ticket.
- The door who gave me a Finish speaker friend Nicole Da Silva Fleck (Brazil) finds out from the Finnish speaking airline staff that her luggage was lost and gets help from a neighbor who speaks Finnish.
Some other clusters that are worth mentioning:
- Brochures for island beaches These stories almost read like advertisements describing the scenic beauty of the beaches on iconic islands such as Goa, Boracay, Borneo, Maldives, and Phuket.
- Travel minutes Stories written in a detailed “hour by hour, day by day” chronological order
- Jungles and their noises A tiny cluster of stories about the cacophony one finds in forests and jungles.
Di-Similarity Nuclei
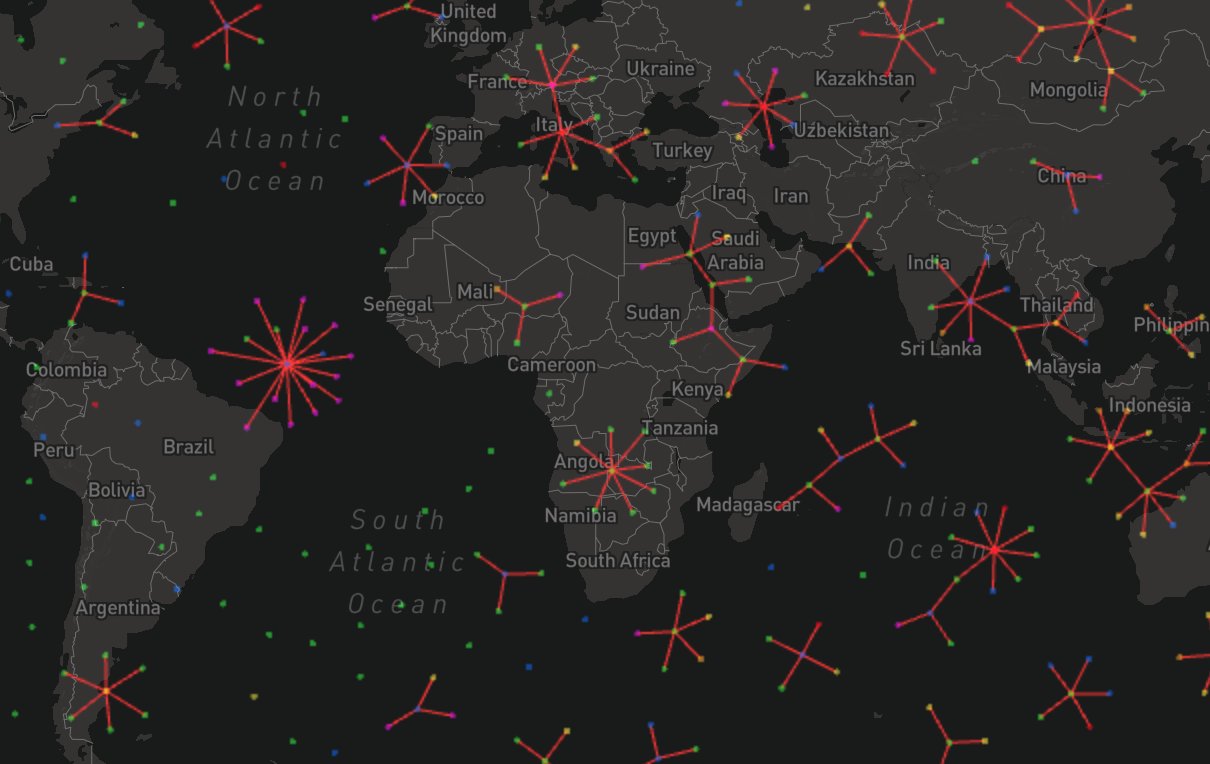
Clustering by similarity distance is intuitive. However, I had a hypothesis that certain stories might be so different that they ought to appear multiple times as the least similar for multiple other stories. I decided to test this by generating clusters using the same force-directed layout approach, but this time the graph edges connect dissimilar stories. The resulting clusters often have at their center what I like to call Di-Similarity Nuclei, stories that the model repeatedly identifies as least similar.
Finding Mongolia’s Silent Secret by Bea Gilbert (UK) showcases how this approach can bubble-up some unique entries. Bea’s submission comes up as the least similar to over 20 other submissions, and a quick glance at her introduction paragraph makes it obvious that her writing style (and choice of words) is one of a kind:
A breadcrumb trail of skulls studs the forest as we labour North. Each beckons a reliving of the previous evening, where a goat hangs dead in the dark. Pearly skin is tethered taut to the swollen canopy of a ger, scuffed hooves still outstretched, stubbed into the gravel. […] My journey to this point had been punctuated by clutter, clobber, noise. An airport taxi driver with a wince-inducing cough delivered me into Ulaanbaatar: a grey and car-choked contradiction between Soviet encroachment and a disorganised lunge at modernisation.
Unfortunately, there are many stories where the writing style is not of a great quality. The upside is that these stories will often cluster around another with a significantly different and therefore better style. For example, Don’t Stop by Rhianna Barbaro (Australia), tells of a gentle hike turned a steep climb written in a pleasant style:
As the old rusted and rattling van swept past fields of thriving green rice paddies and unadulterated countryside, my mind rested on what atrocities this idyllic backdrop could be rehabilitating. As we pulled through a sky-blue gate and onto a dirt road driveway, I didn’t expect to see such vibrant painted wood cabins fashioned like treehouses. This was Sunshine House, an orphanage 90 minutes outside of Phnom Penh, and home to over 50 exploited and abandoned children. It was so far removed from my pre-conceived notions of an orphanage. It was a sanctuary; a refuge.
Contrast with these two excerpts for which Rhianna’s entry comes up as least similar:
If we talked about Portugal, you must be remember a famous soccer from Portugal right? Yes, he is Ronaldo. Portugal is identical to Ronaldo, he is a soccer player born over there. If we talk about Portugal, this country is very famous for their soccer histoy. Even in the 2016 Portugal won a Eropa Cup 2016🏆⚽️ and they never stopped being participants in the world cup. Amazing right? But do you know?
I always dreamed to have a voyage and my dream would be accomplished by not doing so by myself so I never stopped dreaming. I never expect to find a sea trip while looking at my resources but the urge and dream neither stopped nor I did anything to stop it rather I always looking for a chance to stand at the front deck and feel myself on a complete different plannet.
Finally, another particularity of these di-similarity clusters is that they occasionally contain foreign-language stories. This is a bit intriguing, as to why for example Our little Big Sur by Adam Heffernan (Ireland) is the least-similar to 20 Spanish submissions. Is it due to solely to language, or did the model learn some meaningful semantics about the Spanish stories that makes them different than Adam’s story? Likewise with Julie Sparkuhl’s Chicken which for some reason is least similar to a half-dozen Arabic submissions.
The How

Data Scraping & Model Training
When I first started working on this project, I figured that I would be doing most of it in python. After all, that’s the de-facto scripting language nowadays and the increasing number of ML tools makes it a natural choice. Sure enough, I wrote the webscraper using BeautifulSoup which made downloading the stories and storing them with the relevant meta-data straightforward. It actually ended up taking longer to download the stories than to write the script, but that’s mostly because Sri Lanka doesn’t have the fastest of broadband connections.
Once the stories were stored into Yaml files, I spent some time choosing what I was going to do with them. There is a lot of NLP packages out there, but Word2Vec and Doc2Vec repeatedly came up as being straightforward to understand and implement and apparently yielded good results. I ended up following a tutorial for GenSim, and sure enough, within a day of some python scripting and experimenting w/ Jupyter notebooks, I had the first results where I could start being able to compare stories.
The neat thing about the Doc2Vec approach is that it is unsupervised, therefore not requiring any labeling. The downside however is that it can be limiting. For example, as discussed above and this Automatic Topic Clustering Using Doc2Vec post, while the vectors generated by Doc2Vec are useful for clustering, they are not necessarily helpful for automatically labeling them.
Graph and Map Visualization
Visualizing the data turned out to be more difficult than I expected. I initially gravitated towards using Dash/Plotly as I had experience with it from a previous DataViz project. It looked promising especially since Plotly has a wrapper for Cytoscape. As I further explored this option, I realized that there wasn’t much that I needed to do on the server side, therefore making it hard to justify the need for using Dash. I also decided to bypass Plotly since I needed to use some of the more advanced features of Cytoscape. The result was a good proof of concept, but due to the large number of nodes, it turned out to be too sluggish to be really usable.
I eventually found VivaGraphJS - hailed as the fastest graph visualization framework. While not as popular as Cytoscape and not as easy to style, VivaGraph has one main advantage: it makes it possible to use WebGL as a renderer. WebGL uses the GPU for generating the visualization, therefore significantly improving the performance and interactiveness.
One part that took me longer than I expected is to layout the nodes on a map. I initially thought that setting a background for the webpage that I can pan and zoom would do the trick, but that turned out to be somewhat complicated due to the different frames of reference between the screen and the WebGL canvas. When I eventually got it to work, I wasn’t satisfied as the quality of the background deteriorated. Instead I turned to Mapbox which provided a few functions for projecting and back projecting between the two coordinates. It still required some coding and experimenting to properly handle min/max zoom and panning boundaries, but the results were much more satisfying.
Web Framework
The learning curve for VivaGraph was a bit steeper than one would hope for, but that’s mainly because I was not familiar with developing in Javascript. Remember, I went from expecting that I’d be mostly coding in python, to suddenly having to understand JS closures, promises, webpack, and npm! And to make matters worse on myself, I was also learning how to use Vue.js. Vue made it possible to easily add components to interact with the stories such as the searchbox, the reading pane, and the layout options box.
Had I stuck with Dash (which uses React.js for its components), it’s likely that things would have been a bit easier. The upside is that in the process, I now understand a lot more about Javascript and reactive frameworks.
What’s Next?

I am happy with the state of the project so far: it is possible to easily explore stories, find relations between them, and identify interesting ones. However, there are some additional features that I would love to spend some time on, specifically:
-
Implement story generation. Perhaps using Bi-directional LSTM as described in this series of posts. Indeed, it would be interesting to see if a model can generate a story that is most similar or least similar to a submission (or a cluster of them).
-
Illustrating stories: It would be cool to find a way to suggest a “cover picture” for each story. Since the text is too short to be summarized, this approach would serve to provide at a quick glance of the content of a story. Perhaps using Attentional Generative Network?
-
Make it possible to directly link to a story or specific layouts. On the same vein, it would be nice to be able to favorite or vote on stories.
-
Fix interface bugs: Although I spent a lot of time polishing it, the interface is still buggy and occasionally there are corner cases that can throw the display into weird behaviors.
-
Make all of the stories text searchable. Right now, only metadata is searchable. Making all of the text searchable will likely require a server-side implementation, or moving the stories into a database.
I started a new job this week, so we will see how much free time I have to work on these features. If someone wants to get their hands dirty with it, all of the code is on github. Feel free to fork and submit pull-requests.